Diffusion models
In this article I want to tell you about diffusion models, which is an actively developing approach to image generation. Recent research shows that this paradigm can generate images of quality on par with or even exceeding the one of the best GANs. Moreover, the design of such models allows them to surpass two main GANs’ weaknesses, i.e. mode collapsing and sensitivity to hyperparameter choice. However, the same design, that makes diffusion models so powerful, makes them considerably slower on inference.
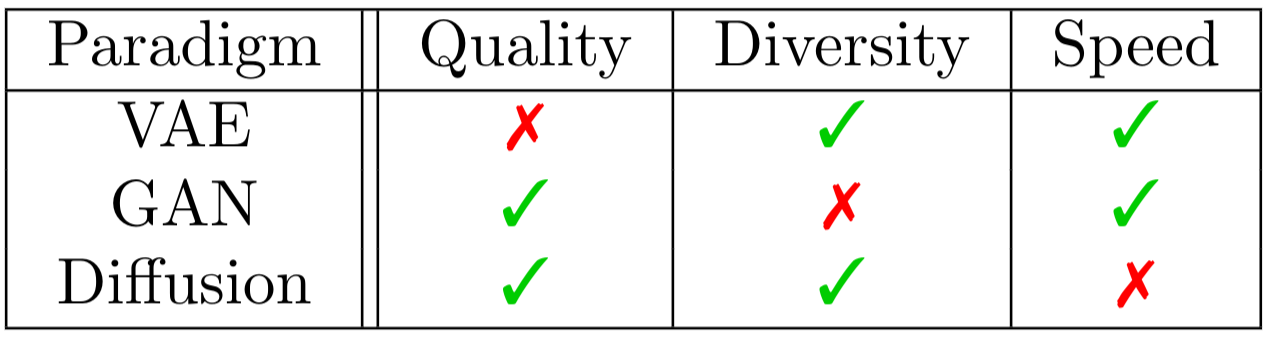
| Table taken from Aran Komatsuzaki’s blog post. |
Read more →